






Europe, and the world, is currently experiencing a major health crisis due to the COVID-19 coronavirus. Restrictions in terms of…
Tekijät | Authors

Can algorithms become start-ups’ crystal ball? The use of AI to predict start-up survival
Background
Professional ventures capitalists (VCs) have for years lived in a world in which, on average, eight out of ten investments in series A-B do not deliver a substantial return on investment. The remaining two investments should, in this context, pay for the other eight (of which five are likely to fail completely) and generate the return asked by the limited partners, the investors in the VC funds. The situation is even bitter for investments in early-stage start-ups (seed capital) for which very limited data are available, and in which investors are oftentimes less “professionalized” than venture capitalists and other corporate investors. When it is obvious than an average increase from two to three profitable cases (meaningful returns) in series A-B would greatly increase the profitability of funds, this is easier said than done.
Some of these investors have used software tools to manage their portfolios and organize their investments for decades (e.g. Shareworks/Capshare by Morgan Stanley, Carta…). These tools have allowed them to harvest operational data from investments, such as tracking the investees and percentage of equity, and provided metrics to evaluate portfolio’s performance, vintages, etc. With the raise of connectivity and the birth of Internet, start-up platforms that helped crunch information, such as Crunchbase, also made their way into the investors’ catalogue of resources. In addition, platforms to organize investment syndications (Seedrs, startupxplore, InnoEnergy VC Community…) also flourished.
In more recent years, investors actively started looking at using software to de-risk investment decisions (Gust, CB insights…) and, as a logical step forward, the use of big data, machine learning and artificial intelligence, to predict start-up success, started to become a topic of interest. The use of such technologies promises a potential to achieve more profitable funds thanks to better-informed investment decisions, backed with computer-analyzed data. As the interest on the topic increased, it also gained traction in academia, and research on how AI, datamining, data crunching, and other technologies, can be used to predict start-up success started to appear (e.g. Antretter et al 2018; Dellermann et al 2017; Sharchilev et al 2018).
InnoEnergy’s story
InnoEnergy SE is a European company fostering the integration of education, technology, business and entrepreneurship and strengthening the culture of innovation. The challenge is big, but our goal is simple: to achieve a sustainable energy future for Europe. Innovation is the solution. New ideas, products and services that make a real difference, new businesses and new people to deliver them to market.
At InnoEnergy we support and invest in innovation at every stage of the journey – from classroom to end-customer. With our network of partners we build connections across Europe, bringing together inventors and industry, graduates and employers, researchers and entrepreneurs, businesses and markets.
We work in three essential areas of the innovation mix:
• Education to help create an informed and ambitious workforce that understands the demands of sustainability and the needs of industry.
• Innovation Projects to bring together ideas, inventors and industry to create commercially attractive technologies that deliver real results to customers.
• Business Creation Services to support entrepreneurs and start-ups who are expanding Europe’s energy ecosystem with their innovative offerings.
Bringing these disciplines together maximises the impact of each, accelerates the development of market-ready solutions, and creates a fertile environment in which we can sell the innovative results of our work.
As a company, InnoEnergy delivers innovation as an output but also applies innovation on its management. In line with this philosophy, InnoEnergy is always searching for new ways of managing innovation with the objective to continuously improve the company’s performance. Benchmark is an obvious method to achieve this objective, and a trend such as the one described in the background section, immediately caught our attention.
InnoEnergy has been able to position itself as a forerunner when it comes to the development of processes, methodologies and tools aimed at de-risking investment decisions and helping start-ups achieve their objectives. An example is E2Talent®, which is InnoEnergy’s start-up team assessment solution that measures entrepreneurial (team and individual) competences. Through the combination of software and human-based exercises we have been able to successfully map more than 800 entrepreneurial profiles in start-ups teams (more info).
It is partly through the use of its innovative processes and tools (e.g. E2Talent) that InnoEnergy has managed to achieve a 97% survival rate for start-ups graduating from InnoEnergy Highway® acceleration programme.
An introduction to the use of AI to predict start-up success
In our day and age, in which a large majority of data are computerized and shared, data scientists have become crucial in a variety of organizations but they, like the rest of us, face challenges related to the amount of generated data. Big data, which we could define as data containing great variety, which are created and acted upon at a high speed, and which have great volume, have become both a challenge and an opportunity. Being able to arrive to useful information is becoming increasingly challenging and there is a need to rely on automatic processes to make sense of enormous datasets.
Data mining as a topic arose in early 2000 as the “process of extracting implicit and previously unknown information with potential from a dataset” (Witten et al. 2000). In their paper, Witten et al. (2000) explicitly pointed towards the creation of computer programs able to crawl through databases and make accurate predictions. A very straightforward example is the use of outlook, temperature, humidity, and other factors, together with a model, to come up with weather forecasts. On the same topic, Berry and Linoff provided in 2004 a more business-centric definition for the concept of data mining as “a collection of technological tools and techniques to support companies by providing useful knowledge” so that companies can make informed decisions.
It was in this context that the topic of using data mining, and subsequentially AI, to predict start-up success started to become relevant. As we can see, it is a topic that leverages both the world of business and information systems and for which a large amount of external data is needed to make predictions. Harvesting all these data is challenging but, not so long ago, in 2012, only 0.5% of all available data in the world was used for analysis (Burn-Murdoch, 2012).
The situation of data extraction now in 2020 is very much the same as when the concept of data mining was development two decades ago but with two great differences: databases are more distributed (online) and the amount of data is immense compared to that available in the beginning of the century. In addition, more and more companies are using data to inform their decisions. With an estimated 463 exabytes of data created every year in 2025 (Desjardins, 2019), majority of people and companies are nowadays aware of the fact that the amount of data available is vast.
What has not changed is the need of a model that can factor in all the extracted data through data mining. Through the process that has become to be known as data crunching, as the preparation and modelling of data through processing, sorting and structuring, models can be used to make predictions. In order for these models to be accurate and efficient, the factors need to be quantifiable and the data need to be automatically mined from distributed sources and databases in the Internet.
The first source from which data can be mined for prediction purposes is web platforms such as Crunchbase and the like. These websites are able to crunch an enormous amount of information about start-ups’ track record. As an example, Crunchbase has start-up data available on general company information, funding rounds, patents, team and recent news.
A related source is social media such as LinkedIn and Twitter. LinkedIn and LinkedIn Sales Navigator have for instance extensive information on companies and professional profiles but, mining data from this social network is an arduous job due to LinkedIn anti-scraping technologies. More innovative approaches, such as the one used by Antretter et al. 2018, are also using other social medias to predict start-up success. In the case of Antretter et al. 2018, and as we will later see in detail, Twitter was used to measure social appreciation and accurately predict new venture survival. Data related to the team, such as years of experience, sector experience and other relevant metrics, can also be mined from this subset of web platforms.
Another web source that can be utilized for data mining are public institutions websites with public financial information and relevant statistics. Information from national statistic centers, such as Tilastikeskus in Finland or Eurostat for the European Union, can provide meaningful data to assess market potential, demographic information, trends, etc. Similarly, patent databases can be useful outlets for data mining.
A review of three AI prediction models from academic literature
An increasing number of academic papers are addressing the topic of how AI can predict start-up success and the results are starting to be promisingly accurate. We will now briefly review three of these papers that illustrate three distinct, though related, approaches in the literature.
As a start, Sharchilev et al. 2018 provide a comprehensive example of an AI model developed to predict start-up success and provide some of the most common building blocks of such models. In their words, the aim of the paper is to investigate the potential of “(early-stage) start-up prediction (…) by using a very rich set of signals from open sources”. These signals are described below in Table 1 and are divided into five categories covering different aspects of start-ups.
Table 1. Metrics used in Sharchilev et al. 2018
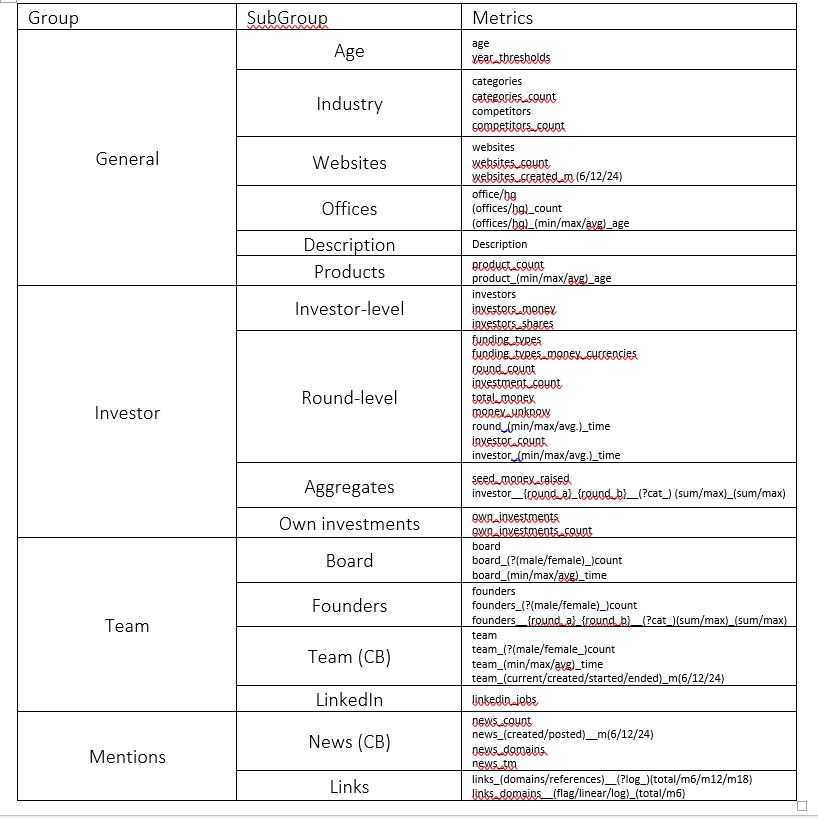
The first category of the model looks at different types of information readily available under the category “General”. This category comprises the most basic information and “gives a general idea of where the company currently stands”. This comprises aspects such as age, industry (sector and competitors), start-up’s websites, start-up’s offices, description of the start-up and products. These different categories are mostly measured as “number of” (#), for example: number of “websites”, number of industry sectors in which the company operates, number of headquarters, product count…
In addition to these general metrics, some signals are measured by taking time into account, such as the ones measuring the number of products over time, the number of websites created in the last 6/12/24 months, and others. Taken time into consideration when looking at start-up information is something we often see in innovation literature to analyse how innovative companies are. For example, Boston Consulting Group (2006) considered new product development speed as the most important metric for innovation performance and 3M’s vitality index, as the KPI measuring the percentage on sales for products that did not exist x (usually five) years ago, is among the most preferred ways to measure innovation performance.
The second set of metrics related to investor features. Factors from this category “capture the information about the startup’s history of funding and engagement with investors”. As I discussed previously in the TALK magazine, being able to bring investors on board is critical and it greatly influences start-up survival and potential success. Features under this category comprised: number and types of previously secured funding rounds, amounts of investments attracted on each round, statistics of previous investors that reflect their historical success both in a specific industry and globally, etc.
Similarly as before, majority of the metrics are counters of aspects such as number of investors or number of rounds closed, while other are aggregated numbers, like the total amount raised in seed rounds or own investments made by the founding team. In addition, funding types is also emphasized as its own signal.
As also discussed elsewhere (see above), start-up team is regarded by many as the most relevant aspect linked to start-up success, and the third category of signals comprises people features. In the words of Sharchilev et al. (2018) “while a company’s funding history reflects the external evaluation of a venture’s potential, it is the company’s team that drives its development internally”. Here we see once again signals related to “number of” different aspects such as number of founders, or number of LinkedIn jobs, but also metrics on the proportion of male/female profiles in the board, founders and the team. Literature in the role of diversity in innovation, creativity and on having successful teams, is extensive (e.g. Cheng and Groysberg, 2020; Hewlett et al. 2013; Reynolds and Lewis, 2017) so such metrics make a lot of sense when aiming at predicting innovative start-up success. Moreover, the time factor was again taken into account with metrics on how the size of the start-up, and the size of the board, evolved overtime, which is very relevant information to estimate the speed at which the start-up is growing.
In order to be able to capture these team metrics, Sharchilev et al. (2018) needed to collect data from web platforms such as Crunchbase but also “incorporate fine-grained information about staff experience from LinkedIn profiles and incorporate this information for people who specified their LinkedIn profiles on Crunchbase”.
Last category of metrics deserves some special consideration of its own. Online mentions, “a detailed crawl of a start-up presence on the web”, were considered separately with data coming from Crunhbase, LinkedIn and also from crawling the Internet in the pursue of data. Data sources ranged from “articles on major financial news websites to commentaries on specialized discussion boards”. The use of this type of data was motivated by the “wisdom of the crowd, a paradigm stating that aggregation of a large set of opinions and/or ideas from a large group of individuals tends to lead to better insights or predictions than given by individual experts”. Specifically, different types of metrics were calculated as both aggregated statistics of a start-up’s online presence (total number of mentions in the last 6/12/18 months, unique domains mentioning the start-up, etc.) but also individual mentions of the company in different domains. Interestingly, these features were among the strongest predictors overall.
Similarly, Dellermann et al. (2017) aimed at putting together human and AI intelligence by also capitalizing on the wisdom of the crowd. In their own words, their research aims at combining “the complementary capabilities of humans and machines in a hybrid intelligence method”. Their vision is that AI will make better decisions than humans but, in complex and creative environments, it is still questionable whether machines are superior to humans. With this standpoint in mind, they embarked into creating this hybrid intelligence method that allows to rip the benefits from both machine and collective intelligence.
Regardless of the origin of the data, Dellermann et al.’s (2017) prediction model categorizes the factors into five different categories: meta, value proposition, market, resources and commitment of 3rd party support. They also categorized signals as either hard, easy to quantify and categorize (e.g. industry, technology, team size), or soft (e.g. innovativeness, personality of entrepreneur). The factors used are enumerated in Table 2.
Table 2. Taxonomy of Signals for Prediction Input
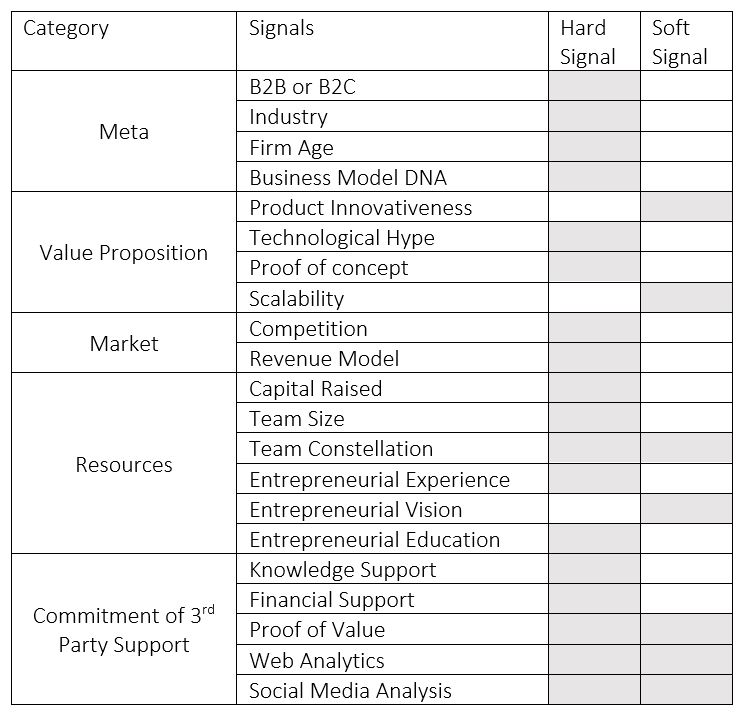
In their research, the collective intelligence is brought into the picture by asking human participants to rate start-ups on a multi-dimensional 7-point Likert scale which is built based on Fitzsimmons and Douglas’ (2011) model of the most relevant dimensions of start-up success: feasibility, scalability, and desirability. This is done by using two instances of collective intelligence: a crowd of non-experts and an expert crowd.
The first category in their research relates to meta-data including aspects also present in Sharchilev et al.’s (2018) research, such as age or industry. In Dellermann et al.’s (2017) paper, business model is also taken into account by looking at whether start-ups used a freemium platform, long tail model, subscribers, etc.
The second category looks at value proposition and combines aspects such as technological hype, measured by Garnert Hype Cycle (more info) or whether a prototype had already been created, which is in line with methodologies such as Technology Readiness Level (more info). The other two aspects measured under this category are left to the crowd to evaluate: scalability and product innovativeness. This decision seems is hardly debatable because one can argue that these two signals are rather subjective and also that mining automatically processed data for them might be challenging, if not impossible.
While the third category brings the market into the picture by analysing revenue model and the competitors in a relatively similar manner as Sharchilev et al. (2018), category number four looks at the internal resources of the company. This latter category mostly concentrates on hard signals such as capital raised, team size, and entrepreneurial experience. In addition, crowd’s knowledge is mobilized to assess entrepreneurial vision and team constellation (diversity of background).
Last category looks at how much the start-up has managed to harvest support from external third parties by looking at aspects such as whether the start-up has been in acceleration/incubation programs, which type of external funding the start-up has been able to secure and how much support has been raised from pilot customers (# of). In addition, and similarly with Sharchilev et al.’s (2018) research, web analytics and social media analysis (twitter in this case) were assessed. An interesting aspect brought in in this section is the mention of sentiment analysis under the social media subcategory. Unfortunately, not much information is given on how this sentiment analysis was performed but the signals under social analysis are marked as both hard and soft.
Following on the topic of social media analysis, other papers, such as the one of Antretter et al. 2018, follow a different approach by focusing solely in the identification of one aspect as a predictor for start-up success. In their research, Antretter et al. (2018) put their efforts on the topic of social media analysis, Twitter once again, by elaborating on a metric called online legitimacy. This metric is then used as a predictor for start-up survival. As they write, “research indicates that interactions on social media can reveal remarkably valid prediction about future events” and, as a proof, they reviewed more than 187,000 tweets from 253 new ventures to accurately discriminate failed ventures from surviving ventures in up to 76% of cases (Antretter et al. 2018). An enumeration of the variables they explored is portrayed in Table 3.
Table 3. Description of variables for the elaboration of the online legitimacy metric (Antretter et al. 2018)
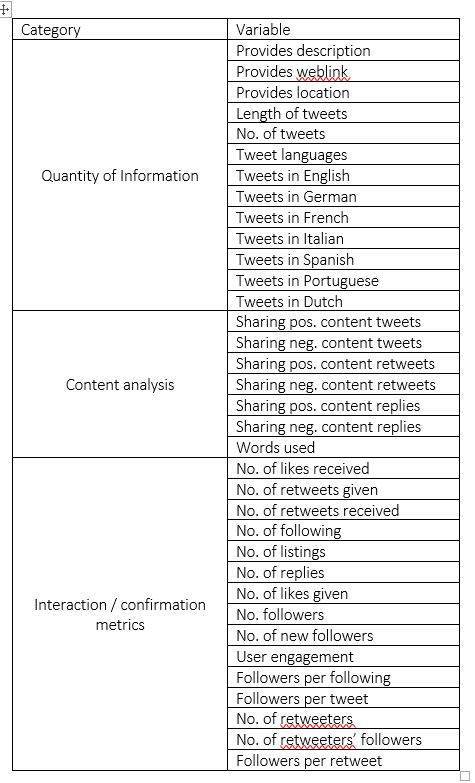
As we can see from Table 3, data are categorized into three categories, namely, quantity of information, content analysis and interaction/confirmation metrics. As we can easily infer from category one, these variables concentrate on quantifiable information such as the number of tweets, number of tweets per language and length of the tweets. In addition, more descriptive information, such as the existence of description, location or weblink, is assessed in here.
Second category, content analysis, is the cornerstone of the article in which positive and negative judgements, contributing to the online legitimacy construct, were identified in tweets, retweets and replies. This was achieved by applying a “multilingual dictionary-based sentiment analysis, which is increasingly being used in management and entrepreneurship research” and using Linguistic Inquiry Word Count (LIWC) to capture positive and negative emotions in English, French, German, Spanish, Italian, Portuguese and Dutch Twitter messages”
In addition, interaction/confirmation metrics were measured within category three with signals such as number of likes, number of retweets or number of followers. These factors give an idea on how much interaction, impact and reach, the start-up communication had in social media (virality).
Final thoughts and conclusions
The topic of how AI can help forecast start-ups’ success and survival is at its infancy, but it is becoming mature rapidly and is delivering fairly accurate results. As the use of AI for this matter is only to increase in the future, some interesting avenues are opening.
As we have seen from the examples above, the topic of using AI to predict start-up success goes beyond the orthodox practice of enumerating and then measuring internal start-up factors. As mentioned by Sharchilev et al. (2018) start-up factors related to start-up online presence were among the strongest predictors overall. Dellermann et al. (2017) and Antretter et al. (2018) also emphasized such aspects by either considering these factors or solely focusing on them in their papers. Specifically, Antretter et al.’s (2018) research on online legitimacy seems to go hand in hand with Sharchilev et al.’s (2018) findings.
As we have seen, the wisdom of the crowd/s, the idea that large groups of people are collectively smarter than individual experts when it comes to problem-solving, decision making, innovating and predicting (Investopedia, 2019), is somehow central to these researches. The use of metrics capitalizing on this wisdom is a topic that deserves special consideration because it is becoming increasingly easier to mobilize the crowd, through the use of AI algorithms, and to analyse their response.
In this context, the use of Natural Language Processing (NLP) as a way to quantify the wisdom of crowds to assess online presence, or for instance for team ideality, brings interesting possibilities to the topic of forecasting start-up success. Mining data from professional and personal social networks is not a new topic, as we have already seen, but we are yet to see mainstream analysis of actual posts, articles, and other published material. Data collected through these analyses can complement other metrics used to predict start-up success and increase its accuracy. Altogether, NLP is already used in other contexts, such as identifying emotions for brand monitoring, and its use to quantify online presence, as seen in Antretter et al. (2018), seems to be coming of age.
Another aspect that is likely to increase in the future, and which seems to be a somehow disregarded opportunity, relates to automatic crunch and analysis of statistics to help start-ups identify the right timing. The amount of economic, markets and demographic (sometimes free) data is immense and we already have the tools to mine it, crunch it and analyse it. Putting these data together can help start-ups redirect their target market, identify segments that have been overlooked or decide on timing.
In addition to these more novel ways to forecast start-up success, and as we have already seen, AI algorithms can help crunch more traditionally used data. Data such as start-up sales, funding information, founding team… are becoming increasingly accessible through distributed databases and can be factored in to help start-up success prediction. These data can then be complemented with the wisdom of the crowd. It is precisely due to this opportunity, to bring data from different sources together, as illustrated by Sharchilev et al. (2018), that data mining and AI analysis are such promising technologies.
Even with this enormous potential in mind, social resistance and ethical use of AI should not be forgotten. As a society we have grown accustomed to the vision of a dystopian future in which machines are making decisions and humans have to put up with the consequences. As we move towards a more mainstream use of AI, being able to address ethical questions and ease social resistance will be more pressing than ever. Acknowledging that humans’ intuition, in the form of individual decision making or the wisdom of the crowds, is still valuable can be a first step.
To sum up, we see that investors and other profiles dealing with start-ups have now new “weapons” to predict start-up success in addition to analyzing traditional factors (sales, funding rounds, business model…). Data mining algorithms are allowing us to harvest enormous amounts of data that can be crunched and put together to make better-informed decisions and predictions. In addition, somehow, human intuition and AI can live together, and the very same algorithms are allowing us to capitalize on collective intelligence and harvest the wisdom of the crowd. All these factors come together in the research analysed in here and they slowly, but steadily, make their way into the practitioners’ world and are sometimes pushed to academia by them. In the years to come, if we are able to overcome social resistance and provide answers to the ethical questions that will arise, the use of hard data and the wisdom of crowds might bring us closer to having a “crystal ball” that is able to accurately predict start-up success.
Biography
Antretter, T., Blohm, I., Grichnik, D. and Wincent, J. (2018) Predicting new venture survival: A Twitter-based machine learning approach to measuring online legitimacy. Journal of Business Venturing Insights, Vol. 11, pp. 1-8.
Boston Consulting Group. (2006) The world’s most innovative companies. Business Week Online, Special report—Innovation, April 24, 2006.
Burn-Murdoch, J. (2012) Study: less than 1% of the world’s data is analysed, over 80% is unprotected. The Guardian. Available online: https://www.theguardian.com/news/datablog/2012/dec/19/big-data-study-digital-universe-global-volume. Consulted 4/2/2020.
Cheng. J.Y. and Groysberg, B. (2020) Gender Diversity at the Board Level Can Mean Innovation Success. MIT Sloan Management Review, Reprint 61318.
Dellermann, D., Lipusch, N., Ebel, P., Popp, K. M. and Leimeister, J. M. (2017) Finding the Unicorn: Predicting Early Stage Startup Success through a Hybrid Intelligence Method. Proceedings of the International Conference on Information Systems (ICIS). Seoul, South Korea.

Very interesting! Those predictions can also be of great help later in the life-cycle to startup coaches. While we coaches tend to use our tacit knowledge and intuition to anticipate growth issues in the startup lifecycle, there is potential in ”formalising” our approach to problem anticipation and identification.